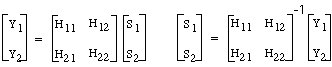|
4.5. Sistemas basados en HRTF.
Los sistemas basados en las funciones de transferencia HRTF, son capaces de simular elevación, distancia y azimut. Esto significa que al menos en principio pueden crear la impresión de un sistema en 3D. En la práctica es algo distinto, debido a las diferencias entre las personas y las limitaciones computacionales, es mucho más sencillo, controlar el azimut que la elevación y la distancia. Aún así, los sistemas basados en HRTF están convirtiéndose en un estándar para sistemas avanzados de 3D. Primeramente hacemos una pequeña descripción del convolotron, que es un conocido sistema 3D desarrollado por la NASA. Describiremos algunas características y terminaremos con distintos modelos HRTF elaborados.
Measuring the HRTF of a KEMAR manikin
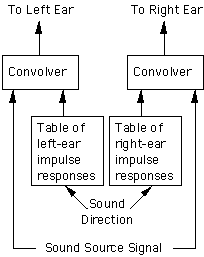
El Convolotrón.
El Convolotron, manufacturado por Cristal River Engineerin, es una manera simple de usar HRTF para el audio especial. Esencialmente consiste en dos convolucionadores cada uno de los cuales convoluciona una misma señal de audio con una respuesta al impulso discreta de la cabeza (Head-related impulse response-HDIR) cogidos de una tabla de valores previamente medidos. La salida va directamente a los auriculares del usuario. Si la HRIR's es suficientemente parecida a la del usuario, entonces obtendremos unos resultados aceptables, la idea básica de funcionamiento • Podemos recrear muchas fuentes haciendo lo mismo para cada fuente. • Podemos tomar en cuenta el movimiento de la cabeza, monitorizando por algún sistema la posición de la cabeza y modificando según la posición de la misma las funciones HRIR's, dando así una sensación de que el usuario se mueve totalmente en un ambiente en 3D y no es simplemente un observador estático en donde el ambiente se mueve con él, consiguiendo así un efecto mucho más real. • Las tablas las podemos crear teniendo en cuenta solamente los parámetros de azimut y elevación, dejando la distancia de la fuente (distinta para cada oído) para utilizar efectos de rango/amplitud. • El número de HRIR's almacenados previamente puede reducirse drásticamente analizando unas funciones HRIR's críticas en el espacio y posteriormente hacer una interpolación para hallar el resto. Esto es, recordemos que dependiendo de la posición de la cabeza y de la fuente tendremos unas HRIR's distintas, así pues resulta muy engorroso hacer un muestreo de todo (si acaso impracticable). • Los ecos y la reverberación de la habitación se pueden añadir incluyendo un modelo simulado de una habitación. • El sistema puede ser personalizado para un individuo particular midiendo y usando las funciones HRIR's de dicha persona. Sin embargo, no importa como implementemos el esquema, la idea principal es generar unas señales adecuadas para ambas orejas con una convolución a tiempo real de la señal original monoaural, con unas tablas tabuladas de respuesta al impulso (HRIR's). Auriculares vs AltavocesLos auriculares simplifican el problema de enviar distintas señales a cada oído pero sin embargo presentan graves inconvenientes, sobretodo en el campo de la realidad virtual. Así podemos enumerar algunos de ellos:
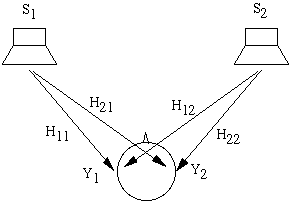
Los altavoces resuelven la mayor parte de estos problemas, pero no está muy claro como dar un sonido binaural. Una solución es una técnica llamada cross-talk-cancelled stereo (or transaural stereo)
La idea básica se ve muy bien en el dominio de la frecuencia. En la figura de arriba se ven las señales S1 y S2 que salen de los altavoces. La señal Y1 que alcanza la oreja izquierda es una mezcla de S1 y el crosstalk de S2. Así para ser más precisos Y1 = H11 S1 + H12 S2, donde H11 es la HRTF entre el altavoz izquierdo y la oreja izquierda y H12 es la HRTF entre el altavoz derecho y la oreja izquierda. Similarmente Y2 = H21 S1 + H22 S2. Si pudiéramos usar auriculares podríamos saber Y1e Y2, que son las señales que recibimos en los dos oídos respectivamente. El problema es encontrar las señales apropiadas S1 y S2 que nos dan los resultados deseados. Esto matemáticamente es bastante sencillo, simplemente invertir las ecuaciones:
En la práctica invertir las matrices no es tan sencillo. • A frecuencias bajas, todas las funciones de transferencia son prácticamente idénticas (ya vimos por qué), y por lo tanto la matriz es singular (el determinante es cero). Afortunadamente, en recintos reverberantes, la información de baja frecuencia no es muy importante para la localización. • Una solución exacta produce una respuesta al impulso muy larga. Este problema es notable cuanto más alejada esté la fuente con respecto el punto medio entre los dos altavoces. • El resultado depende de la posición relativa del usuario con respecto a los altavoces. (Los resultados óptimos se obtienen en un punto llamado sweet spot, que es una posición asumida cuando las ecuaciones anteriores son invertidas. Si se hace bien, la técnica crosstalk-canceled stereo puede ser muy efectiva, consiguiendo variar tanto el azimut como la elevación. La fuente la podemos situar fuera de la línea que une los dos altavoces. Sin embargo, puesto que el stereo cross-talk-cancelled aun necesita señales binaural, limitaremos nuestras observaciones permanentes a sistemas auriculares. Registro de la posición de la cabeza.Cuando utilizamos los auriculares, si el usuario se mueve o mueve la cabeza, las señales enviadas a los auriculares no varían, produciendo así la sensación de que la fuente de sonido se mueve con el usuario. Esto no se puede dar en aplicaciones de realidad virtual. Es más, incluso algunos efectos espaciales son debilitados o incluso totalmente anulados. Esto es particularmente un problema para fuentes que se suponen directamente en frente o detrás del usuario porque la velocidad de variación de las variables, es mucho más rápida para esas direcciones. Así, un resultado típico es que las fuentes aparezcan demasiado cerca o incluso dar la impresión que se originan en la cabeza. Una solución posible es usar un aparato que tenga constancia de la posición relativa de la cabeza con respecto las fuentes ó fuente (head tracker) y que lo haga periódicamente; variando las HRIR's según los datos obtenidos. En este sentido, a la hora de diseñar, a parte del coste, fiabilidad y precisión, otros dos aspectos han de ser tenidos en cuenta:
Versiones Modeladas y experimentales de HRTF's.Debido a que las funciones HRTF's son muy complejas, la mayoría de los sistemas desarrollados han dependido de funciones medidas experimentalmente con el KEMAR. Sin embargo, los efectos de elevación y de azimut son particularmente sensibles a las diferencias individuales. Han surgido cuatro aproximaciones diferentes para estas funciones:
Usar un modelo HRTF conteniendo parámetros que pueden ser adaptados a cada individuo. Para estos modelos sugerimos ir a la bibliografía, ya que es un tema extenso y que se sale del propósito de este trabajo.
|